Description: Homo sapiens coronin, actin binding protein, 1C (CORO1C), transcript variant 1, mRNA. RefSeq Summary (NM_001105237): This gene encodes a member of the WD repeat protein family. WD repeats are minimally conserved regions of approximately 40 amino acids typically bracketed by gly-his and trp-asp (GH-WD), which may facilitate formation of heterotrimeric or multiprotein complexes. Members of this family are involved in a variety of cellular processes, including cell cycle progression, signal transduction, apoptosis, and gene regulation. Three transcript variants encoding two different isoforms have been found for this gene. [provided by RefSeq, Feb 2013]. Transcript (Including UTRs) Position: hg19 chr12:109,038,885-109,096,774 Size: 57,890 Total Exon Count: 11 Strand: - Coding Region Position: hg19 chr12:109,041,179-109,096,725 Size: 55,547 Coding Exon Count: 11
Diabetes Mellitus, Type 2 Laura J Scott et al. Science (New York, N.Y.) 2007, A genome-wide association study of type 2 diabetes in Finns detects multiple susceptibility variants., Science (New York, N.Y.).
[PubMed 17463248]
The RNAfold program from the Vienna RNA Package is used to perform the secondary structure predictions and folding calculations. The estimated folding energy is in kcal/mol. The more negative the energy, the more secondary structure the RNA is likely to have.
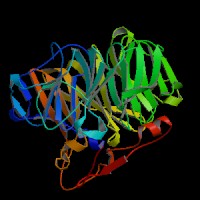
ModBase Predicted Comparative 3D Structure on A7MAP1
Front
Top
Side
The pictures above may be empty if there is no ModBase structure for the protein. The ModBase structure frequently covers just a fragment of the protein. You may be asked to log onto ModBase the first time you click on the pictures. It is simplest after logging in to just click on the picture again to get to the specific info on that model.
Orthologous Genes in Other Species
Orthologies between human, mouse, and rat are computed by taking the best BLASTP hit, and filtering out non-syntenic hits. For more distant species reciprocal-best BLASTP hits are used. Note that the absence of an ortholog in the table below may reflect incomplete annotations in the other species rather than a true absence of the orthologous gene.
 Sequence and Links to Tools and Databases
Sequence and Links to Tools and Databases  Common Gene Haplotype Alleles
Common Gene Haplotype Alleles